
1. 引言
我们就先来介绍一下 Docker Swarm 与 Kubernetes 的核心思想。
2. Docker Compose
我们介绍了 Docker Compose 的用法,它让我们可以将多个 Docker 容器链接成一个组合的功能,这个组合中的所有容器可以被一次性全部部署、启动或停止。
这对于我们单机部署多个相互有依赖关系的 Docker 镜像时,有着很大的帮助。
但对于多个物理机或虚拟主机组成的集群来说,Docker Compose 就力不从心了。我们往往需要一个更高等级的中心化平台去管理和调度整个由 Docker 镜像构成的集群。
3. Docker Swarm
Docker1.12 版本开始,Docker 引擎中原生内建了 Docker Swarm Mode 只要通过 Docker Engine CLI/API 就可以建立并且管理 Docker Swarm 集群,无需额外的安装和设定。
Docker Swarm 将集群中不同的设备划分为两种不同的角色:Manager 和 Worker,它们组成了 Docker Overlay Network 网络机制:
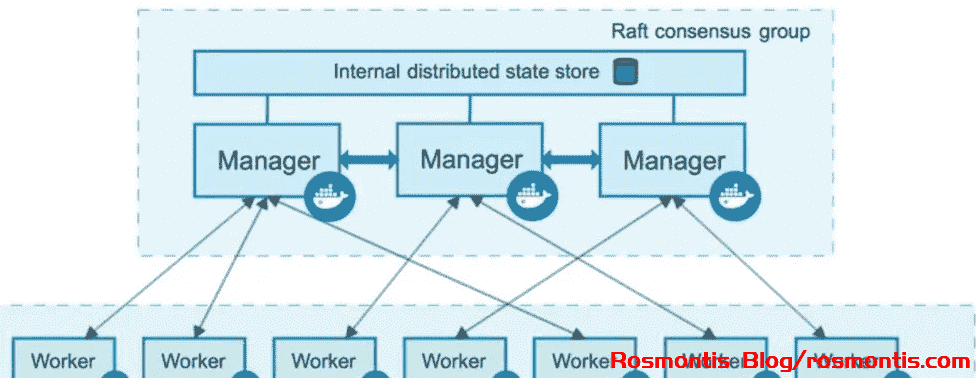

Worker 负责业务容器的运行,Manager 则负责集群的管理。
基于这样的集群管理模式,我们可以实现:
- 自动化跨主机 host 的集群搭建;
- 集群规模的按需缩放,但目前尚不成熟;
- worker 容器宕机后,在冗余的 Worker 主机上自动启动 Worker 来容灾;
- 镜像版本的升级和回滚;
- 支持 Routing Mesh 复杂均衡。
4. Kubernetes
4.1 什么是 Kubernetes
基于 Docker Compose 我们可以实现单机的多 Docker 镜像的依赖管理,基于 Docker Swarm,我们可以实现集群组建与调度。那么,针对线上微服务场景,Docker 原生的所有工具是否已经完全可以满足我们的一切需要了呢?
Google 公司告诉我们说不行,因为:
在大规模集群中的各种任务之间运行,实际上存在着各种各样的关系,处理这些关系才是作业编排和管理系统最困难的地方。
Kubernetes 的设计思想是以统一的方式抽象底层基础设施(计算、存储、网络等)的能力,定义任务编排的各种关系(亲密关系、访问关系、代理关系等),将这些抽象以声明式 API 的方式对外暴露,从而允许平台构建者基于这些抽象进一步构建自己的 PaaS 集群乃至更上层的平台。于是,Kubernetes 便成为了构建平台的基础平台。
相比于 Docker Swarm,Kubernetes 更进一步将平台构建进行了抽象,这深一层的抽象,让 Kubernetes 项目不只是简单地提供编排能力,而是变成了一系列具有普遍意义的、以声明式 API 驱动的容器化作业编排思想。如果将 Docker Swarm 看成是承载了战斗机集群的一架航母,那么 Kubernetes 可以被看作是一个航母设计平台。
由于 Kubernetes 在 K 和最后的 s 之间有 8 个字母,于是人们通常将这个长长的名字简化为 K8s,而在中文发音中,K8s 又恰好与 Kubernetes 十分相似,K8s 也就成为了人们十分喜欢的简称。
4.2 K8s 的抽象
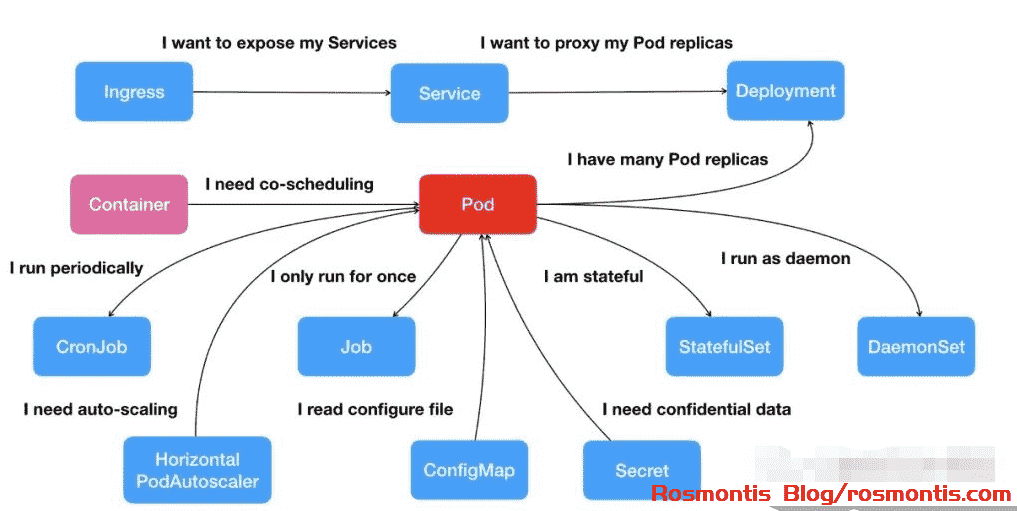
上图展示了 K8s 核心功能的全景图。
4.2.1 Pod
位于上面这个全景图最核心地位的就是 Pod。
若干需要协同调度的容器被封装为一个 Pod,它们在同一个主机上,通过 localhost 进行通信,通过本地磁盘交换文件,因此,K8s 让这些容器共享同一个 Network Namespace、同一组 Volume,从而实现高效的信息交换。
4.2.2 Deployment、Job 与 Cronjob
当我们需要针对同一个 Pod 启动它的多个应用实例时,这些应用实例就被封装在一个 Deployment 中,Deployment 就是这个 Pod 的多实例管理器。
而 Job 封装了只运行一次的 Pod;Cronjob 则封装了需要周期运行的 Pod。
4.2.3 Service
Pod 中的容器要想向外提供服务,就需要绑定到一个 Service,由 Service 代理 Pod 的 IP 地址和端口,从而通过 K8s 平台的功能,让调用者无需绑定到随时可能变化的 Pod 的固定 IP 地址和端口,而是通过调用 Service 动态找到其代理的后端 Pod。
当一个 Service 代理 Deployment 时,针对 Deployment 中的多个 Pod 实例,Service 会以负载均衡的功能进行调用。
4.2.4 ConfigMap 与 Secret
在一个集群中,我们经常会需要维护许许多多诸如密钥、密码键值对等信息,这时,我们就需要定义 Secret 节点,当使用该 Secret 的 Pod 启动时,K8s 会自动把 Secret 里的数据以 Volume 的方式挂载到容器中。同理,还有维护 Pod 所需配置信息的 ConfigMap。
2. K8s 的架构
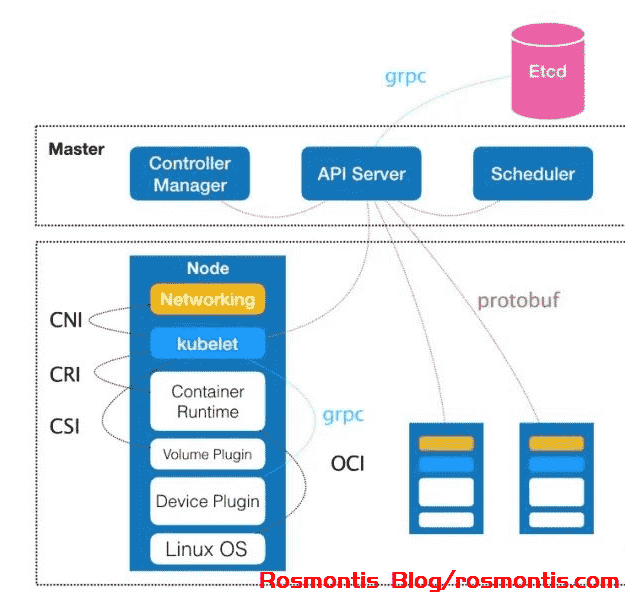
上图就是 K8s 的全局架构。它由 Master 和 Node 两种节点构成,它们分别对应控制节点和计算节点。
2.1 Master 节点
Kubernetes 的 Master 节点即它的控制节点,它由三部分构成:
- kube-controller-manager: 负责容器编排;
- kube-scheduler:负责调度;
- kube-apiserver:负责 API 服务。
整个集群的持久化数据,则由 kube-apiserver 处理后保存在 etcd 中。
2.2 Node 节点
Node 节点即 Kubernetes 的计算节点。它最核心的就是名为 kubelet 的组件,它负责同容器运行时,例如 Docker CRI 进行交互,而这种交互依赖的是一个称作 CRI 的远程调用接口,该接口定义了容器运行时的各项核心操作,比如启动容器所需的所有参数等。
有了 kubelete 的抽象,Kubernetes 可以不必关心你部署的什么容器、使用了什么技术实现,只要你的容器运行时能够运行标准的容器镜像,就可以通过实现 CRI 接入 Kubernetes。
具体实现上,在 Docker 项目中,一般通过 OCI 这个容器运行时规范,将 CRI 请求翻译成对 Linux 系统调用,从而实现 CRI 的调用。
同时,kubelet 提供了 CNI 和 CSI 分别将网络与持久化存储以插件的形式集成到 Kubernetes 中供容器调用。
3. Kubernetes 的部署
基于上述架构,Kubernetes 设计者们通过 golang 语言实现了一系列相互协作的组件,从而实现了 Kubernetes 的可执行程序。
但问题在于,如何将这些二进制可执行文件以及他们各自的配置文件、授权文件、自启动脚本部署到生产环境中去无疑是一项艰巨的工作。
2017 年,Kubernetes 社区推出了使用极为方便的部署工具 -- kubeadm。我们只需要执行下面两个命令就可以部署一个 Kubernetes 集群:
$ kubeadm init # 创建一个 Master 节点。
$ kubeadm join <Master 节点的 IP、端口> # 将一个 Node 节点加入到集群中。4. 用 kubeadm 创建集群
此处我使用的环境 ubuntu20.04,如果你用的是其他版本的操作系统,可以参考官网:
https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
4.1 安装 kubeadm、kubelet 与 kubectl
首先,我们需要安装 Kubernetes 所必需的三个组件:
kubeadm:用来初始化集群的指令。kubelet:在集群中的每个节点上用来启动 Pod 和容器等。kubectl:用来与集群通信的命令行工具。
执行下列命令即可:
$ sudo apt-get update
$ sudo apt-get install -y apt-transport-https ca-certificates curl
$ sudo curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
$ echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
$ sudo apt-get update
$ sudo apt-get install -y kubelet kubeadm kubectl
$ sudo apt-mark hold kubelet kubeadm kubectl4.2 创建集群
4.2.1 准备工作
- 启动 kubelet
完成了上述安装,我们就可以利用 kubeadm 来创建集群了,但首先,我们必须启动 kubelet,让我们启动并设置为开机自动启动:
$ systemctl enable kubelet && systemctl start kubelet- 禁止 swap 分区
swapoff -a- 关闭防火墙与 selinux
$ ufw disable
$ sudo apt install selinux-utils && setenforce 04.2.2 创建集群
接下来,我们就可以执行下面的命令创建集群了:
$ sudo kubeadm init4.2.3 拷贝配置
如果你是在当前机器上第一次启动 kubernetes 集群,你需要按照屏幕上显示的提示执行:
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config4.3 可能的问题
4.3.1 镜像拉取失败
由于官方镜像地址被墙,所以我们需要首先获取所需镜像以及它们的版本。然后从国内镜像站获取。
首先,执行下面的命令获取你所需要的各个镜像的版本号:
$ kubeadm config images list --config kubeadm.conf然后,编写 k8s.sh,注意其中的版本号修改为上面那个命令返回的版本号:
#!/bin/bash
echo "修改docker普通用户权限"
sudo chmod 777 /var/run/docker.sock
echo "1.拉取镜像"
#下面的版本号要对应
KUBE_VERSION=v1.23.5
PAUSE_VERSION=3.6
CORE_DNS_VERSION=1.8.6
ETCD_VERSION=3.5.1-0
# pull kubernetes images from hub.docker.com
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:$KUBE_VERSION
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:$KUBE_VERSION
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:$KUBE_VERSION
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:$KUBE_VERSION
# pull aliyuncs mirror docker images
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:$PAUSE_VERSION
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:$CORE_DNS_VERSION
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:$ETCD_VERSION
# retag to k8s.gcr.io prefix
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:$KUBE_VERSION k8s.gcr.io/kube-proxy:$KUBE_VERSION
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:$KUBE_VERSION k8s.gcr.io/kube-controller-manager:$KUBE_VERSION
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:$KUBE_VERSION k8s.gcr.io/kube-apiserver:$KUBE_VERSION
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:$KUBE_VERSION k8s.gcr.io/kube-scheduler:$KUBE_VERSION
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:$PAUSE_VERSION k8s.gcr.io/pause:$PAUSE_VERSION
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:$CORE_DNS_VERSION k8s.gcr.io/coredns/coredns:v$CORE_DNS_VERSION
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:$ETCD_VERSION k8s.gcr.io/etcd:$ETCD_VERSION
# untag origin tag, the images won't be delete.
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:$KUBE_VERSION
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:$KUBE_VERSION
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:$KUBE_VERSION
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:$KUBE_VERSION
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/pause:$PAUSE_VERSION
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:$CORE_DNS_VERSION
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:$ETCD_VERSION
echo "====================执行完毕======================"
echo "所需镜像:"
kubeadm config images list
echo "已安装镜像:"
sudo docker images
echo "====如果数量不匹配请多执行几次k8s_pull_images.sh====="执行 k8s.sh 之后,再执行初始化命令即可:
$ sudo kubeadm init4.3.2 dial tcp 127.0.0.1:10248: connect: connection refused
是 cgroup 驱动问题。默认情况下 Kubernetes cgroup 驱动程序设置为system,但 docker 设置为 systemd。我们需要更改 Docker cgroup 驱动。
使用你喜欢的编辑器, 编辑 /etc/docker/daemon.json 并添加:
{
"exec-opts": ["native.cgroupdriver=systemd"]
}保存后执行:
$ systemctl daemon-reload
$ systemctl restart docker
$ systemctl restart kubelet然后,重新初始化集群即可:
$ sudo kubeadm reset
$ sudo kubeadm init4.4 kubeadm init 做了什么
执行 kubeadm init 后,很快便完成了集群的创建和初始化,那么,这一过程中到底做了什么呢?
我们打开 /etc/kubernetes 目录,可以看到下面出现了很多配置文件和目录。kubeadm 的初始化工作便是围绕这些配置文件展开的。
主要做了这么几件事:
- 检查环境以来,包括 linux 内核版本、cgroups 模块是否可用、hostname 是否标准、所需端口是否已经被占用等等。
- 创建私钥,由于默认情况下 kube-apiserver 都需要通过 SSL 加密协议才能访问,因此,私钥和证书是必须的,但如果你预先将已有的证书放在 /etc/kubernetes/pki 下,那么,kubeadm 会跳过这一步。
- 生成 kube-apiserver 所需的配置文件 /etc/kubernetes/*.conf。
- 通过 pod 的方式部署 Master 组件,包括:
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- 生成 etcd 的 pod 配置文件,并以 pod 的方式启动 etcd。
- 通过检测 localhost:6443/healthz 来检查 Master 组件是否健康运行。
- 生成 bootstrap token 并将用法打印出来,用来供 Node 节点通过 kubeadm join 加入集群。
- 安装 kube-proxy 和 DNS 两个用来提供集群服务发现和 DNS 功能的插件。
kube-apiserver、kube-controller-manager 与 kube-scheduler 三个 pod 的配置文件都位于 /etc/kubernetes/manifests 路径下,我们可以通过查看和编辑这些 yaml 文件来修改 pod 的启动方式和参数等,也可以借此学习 pod 配置文件的写法。
4.5 进阶 -- 添加自定义配置
kubeadm init 命令支持通过 --config 参数传递 yaml 文件来进行自定义配置,例如我们使用下面的 yaml 配置 kubeadm.yaml:
apiVersion: kubeadm.k8s.io/v1beta2
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
cgroup-driver: "systemd"
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: "v1.18.8"
clusterName: "sample-cluster"
controllerManager:
extraArgs:
horizontal-pod-autoscaler-use-rest-clients: "true"
horizontal-pod-autoscaler-sync-period: "10s"
node-monitor-grace-period: "10s"
apiServer:
extraArgs:
runtime-config: "api/all=true"然后通过执行下面命令即可:
$ kubeadm init --config kubeadm.yaml该配置中,通过 horizontal-pod-autoscaler-use-rest-clients: "true" 让 kube-controller-manager 开启了通过用户自定义监控指标 Custom Metrics 进行自动水平扩展的特性。
5. 通过 kubeadm join 加入集群
5.1 bootstrap token 是什么
首先,上文提到,在集群初始化的最后几步中,kubeadm 生成了 bootstrap token 并将用法打印出来,用来供 Node 节点通过 kubeadm join 加入集群。那么,什么是 bootstrap token?他又是用来做什么的?
新加入到集群的节点首先需要获取存储在 ConfigMap 中的 cluster-info,但用来与集群交互的 kube-apiserver 提供的接口在安全模式下都是需要 ssl 认证的,那么,我们就必须非常繁琐的将证书文件手动放到新的节点中才能进行接下来的操作。bootstrap token 就是用来解决这一步繁琐操作用的,通过 bootstrap token,kubeadm 允许在此时发起一次非安全模式下的通信,从而让新的节点拿到 ConfigMap 中的 cluster-info,从而获得包括授权信息在内的集群信息。
5.2 通过 Taint 机制在 Master 节点中运行用户 Pod
前面已经提到过,Master 节点是不允许运行用户 Pod 的,但是 Kubernetes 提供了 Taint 机制,允许我们去这么做:
$ sudo kubectl taint nodes master foo=bar:NoSchedule这意味着,只有生命了键值对 foo=bar 的 Taint 的 Pod 才允许在 Master 节点中运行,并且除此以外所有其他 Pod 都不能在 Master 节点上运行。
如果要运行一个 Pod,我们就要在 Pod 的 yaml 文件中配置:
apiVersion: V1
kind: pod
...
spec:
tolerations:
- key: "foo"
operator: "Equal"
value: "bar"
effect: "NoSchedule"6. 通过 kubectl 管理集群
6.1 检查节点状态
执行 kubectl get 命令可以看到当前节点的状态:
$ sudo kubectl get nodesNAME STATUS ROLES
AGE VERSIONmaster NotReady control-plane,master 76m v1.23.5我们看到 master 节点的状态是 NotReady,这是为什么呢?接下来我们可以通过下面命令进一步查看问题的原因:
$ sudo kubectl node master除此以外,我们还可以通过下面的命令检查各个 pod 的状态:
$ sudo kubectl get pods -n kube-system
coredns-64897985d-48vxb 0/1 Pending 0
80mcoredns-64897985d-7vxr7 0/1 Pending 0
80metcd-techlog-ubuntux1c 1/1 Running 0
80mkube-apiserver-techlog-ubuntux1c 1/1 Running 0
80mkube-controller-manager-techlog-ubuntux1c 1/1 Running 0
80mkube-proxy-vcvf6 1/1 Running 0
80mkube-scheduler-techlog-ubuntux1c 1/1 Running 0
6.2 部署网络插件
通过上面的命令结果,我们可以看到,master 节点 NotReady 的原因是 coredns 节点处于 Pending 状态,这是因为网络插件尚未部署,只要执行下面的命令部署即可:
$ sudo kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d 'n')"我们也可以通过这个命令部署 Dashboard 可视化插件:
$ sudo kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.0/aio/deploy/recommended.yaml原创文章,作者:Rosmontics,如若转载,请注明出处:https://rosmontis.com/archives/644

评论列表(1条)
在这里,我甚至还能看到K8S的教程。。。